CS224W-Machine Learning with Graph-GNN1
Basics of Deep Learning
- Loss function:
- can be a simple linear layer, an MLP, or other neural networks (e.g., a GNN later)
- Simple a minibatch of input .
- Forward propagation: Compute given
- Back-propagation: Obtain gradient using a chain rule.
- Use stochastic gradient descent (SGD) to optimize for over many iterations.
Deep Learning for Graphs
Setup
Graph .
- is the vertex set
- is the adjacency matrix (assume binary)
- is a matrix of node features
- : a node in ; : the set of neighbors of
- Node Features:
- Social networks: Use profile, User image
- Biological networks: Gene expression profiles, gene functional information
- When there is node feature in the graph dataset:
- Indicator vectors (one-hot encoding of a node)
- Vector of constant 1:
A Naive Approach
- Join adjacency matrix and features
- Feed them into a deep neural net
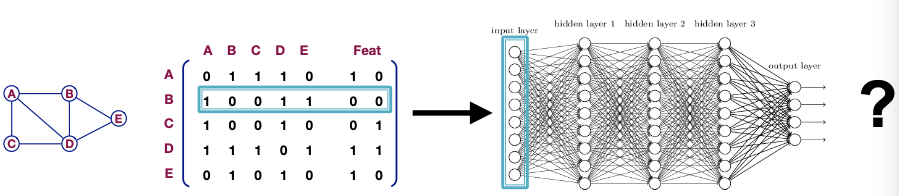
- Issues with this idea:
- parameters
- Not applicable to graphs of different sizes
- Sensitive to node ordering
Convolutional Networks (卷积网络)
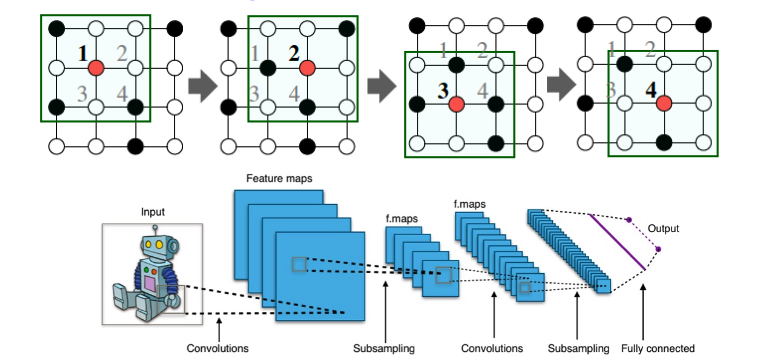
Goal is to generalize convolutions beyond simple lattices Leverage node features/attributes(e.g., text, images)
Real-World Graphs
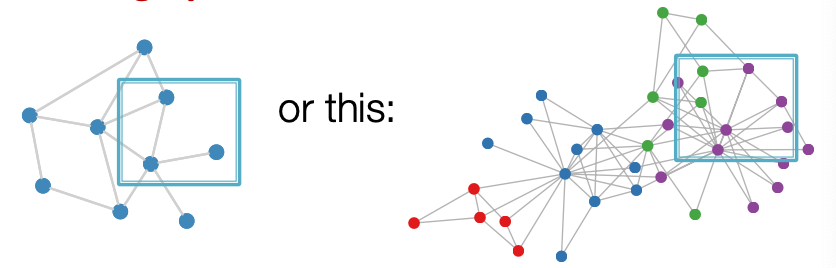
- There is no fixed notion of locality or sliding window on the graph
- Graph is permutation invariant
Permutation Invariance (排列不变性)
Graph does not have a canonical order of the nodes!
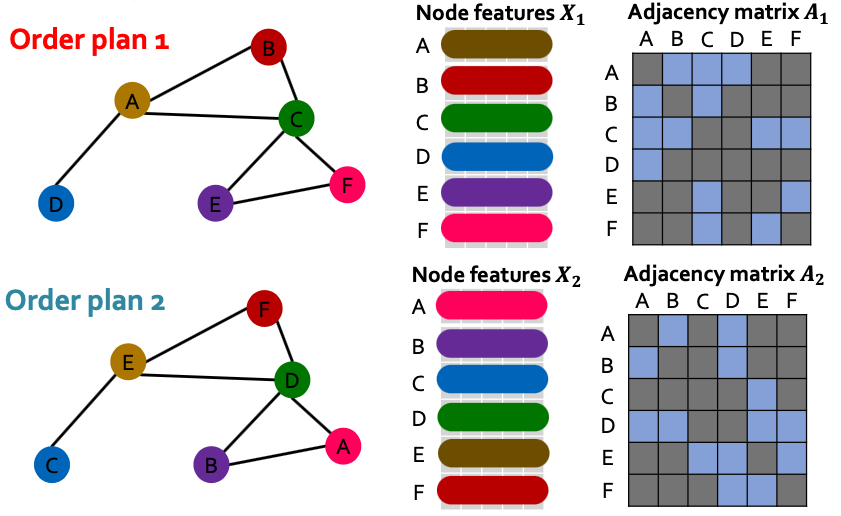
We can have many different order plans.
What does it mean by “graph representation” is same for two order plans?
- Consider we learn a function that maps a graph to a vector then
- In other words, maps a graph to a embedding
- is the adjacency matrix
- is the node feature matrix
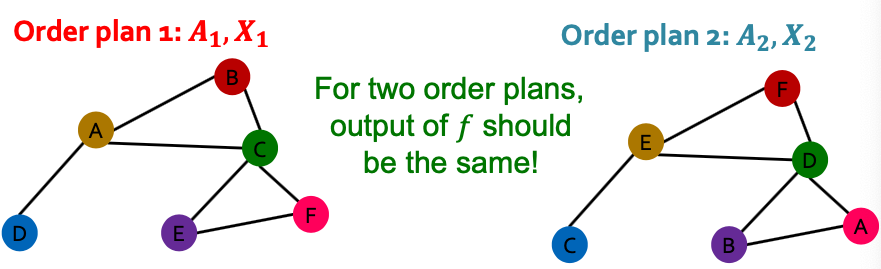
- Then, if for any order plan and , we formally say is a permutation invariant function.
- For a graph with nodes, there are different order plans. (排列组合)
- Definition: For any graph function , is permutation-invariant if for any permutation .
- : each node has a feature vector associated with it.
- : output embedding dimensionality of embedding the graph
- Permutation : a shuffle of the node order. Expamle:
Permutation Equivariance
- For node representation: We learn a function that maps nodes of to a matrix
- In other words, each node in is mapped to a embedding.
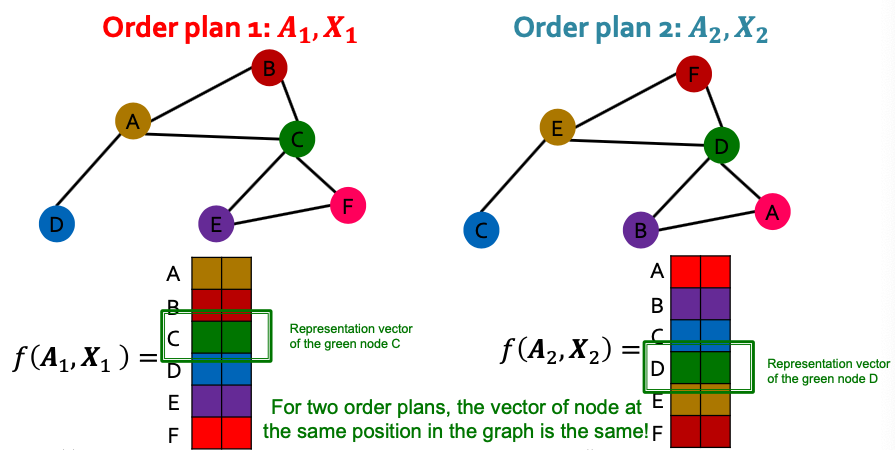
- If the output vector of a node at the same position in the graph remains unchanged for any order plan, we say is permutation equivariant.
- Definition: For any node function , is permutation-equivariant if for any permutation .
- : each node has a feature vector associated with it
- maps each node in to a embedding.
Summary: Invariance and Equivariance
- Permutation-invariant(Permute the input, the output stays the same)
- Permutation-equivariant(Permute the input, output also permutes accordingly)
- Examples:
- Permutation-invariant
-
- Permutation-equivariant
-
- Permutation-invariant
Graph Convolutional Networks [Kipf and Welling, ICLR 2017]
图卷积网络
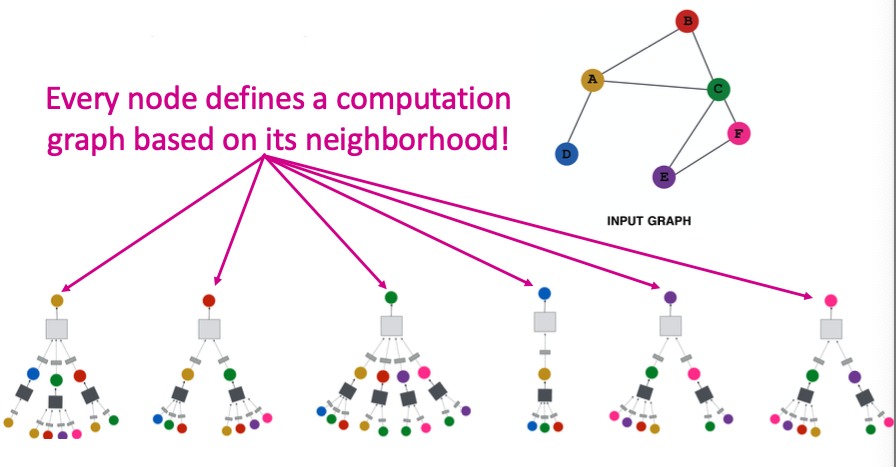
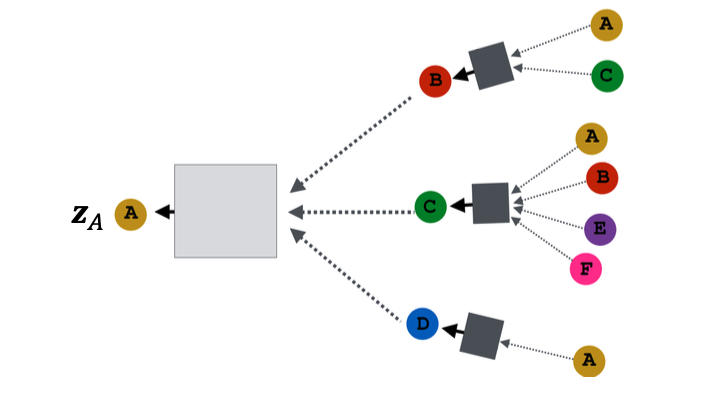
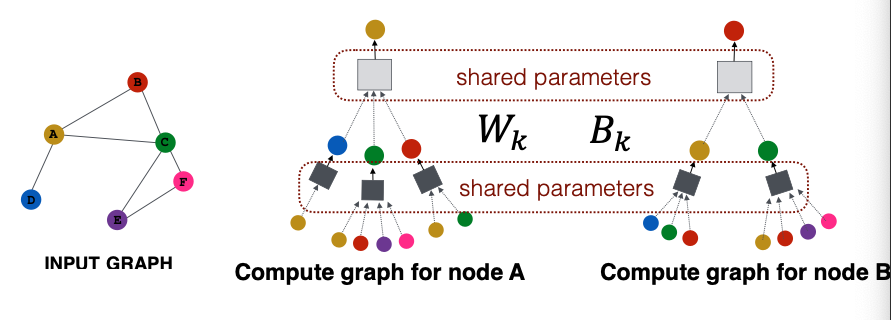
Idea: Node’s neighborhood defines a computation graph
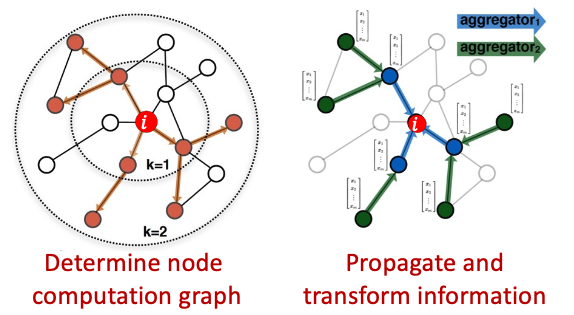
How to propagate information across the graph to compute node features?
Key idea: Generate node embeddings based on local network neighborhoods
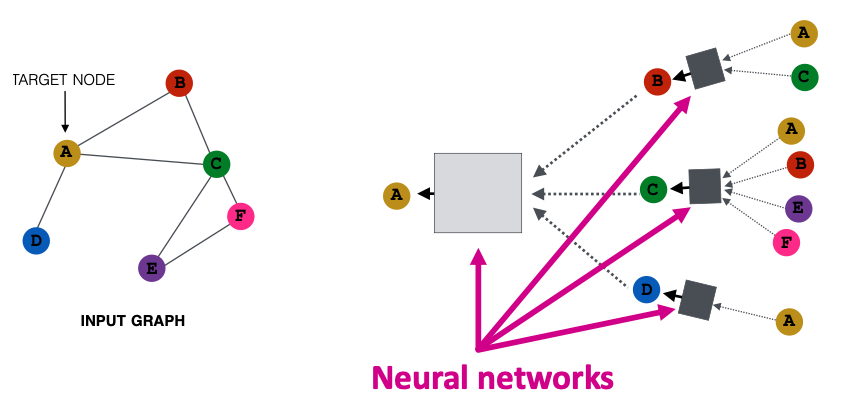
- Nodes aggregate information from their neighbors using neural networks (上图)
- Network neighborhood defines a computation graph (下图)
Deep Model: Many Layers
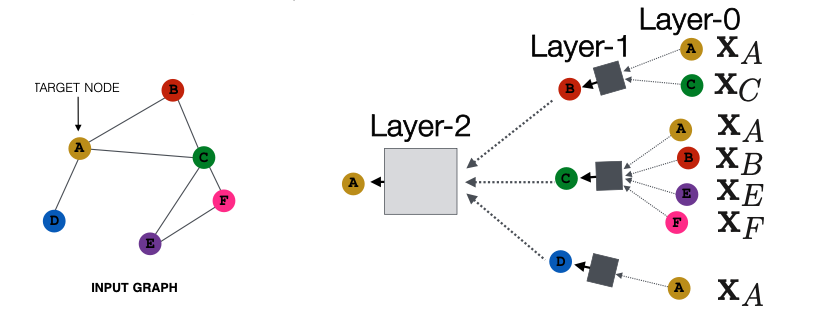
Model can be of arbitrary depth:
- Nodes have embeddings at each layer
- Layer-0 embedding of node is its input feature,
- Layer-k embedding gets information from nodes that are hops away
Neighborhood Aggregation (邻居节点的聚合)
Key distinctions are in how different approaches aggregate information across the layers
Basic approach: Average information from neighbors and apply a neural network.
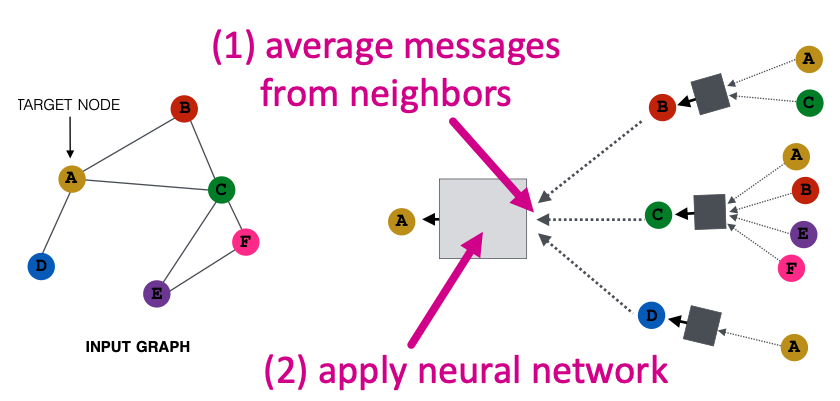
- Initial 0-th layer embeddings are equal to node features
- : Non-linearity (e.g., ReLU)
- : Average of neighbor’s previous layer embeddings
- : embedding og at layer .
- : total number of layers
- : Embedding after layers of neighborhood aggregation
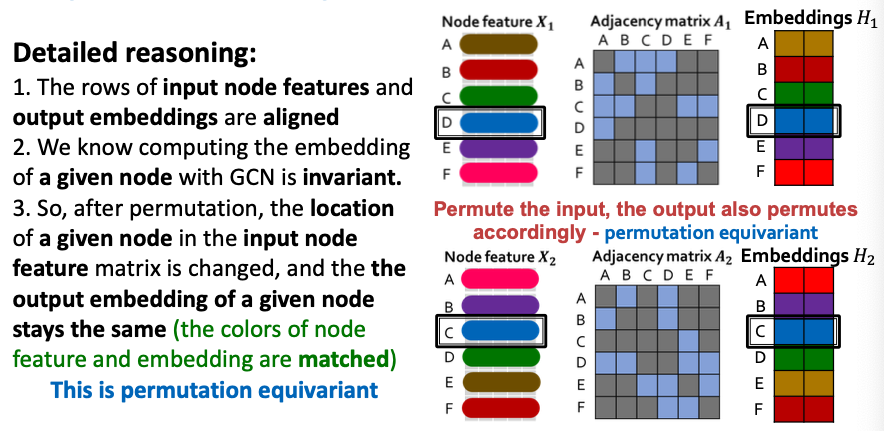
GCN: Invariance and Equivariance
Invariance and Equivariance Properties for a GCN?
- Given a node, the GCN that computes its embedding is permutation invariant
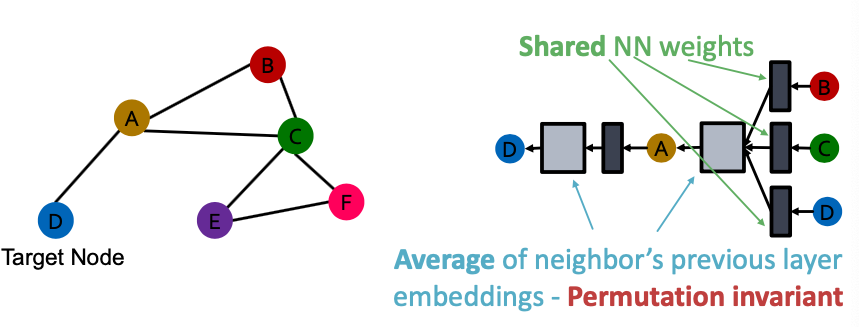
- Considering all nodes in a graph, GCN computation is permutation equivariant
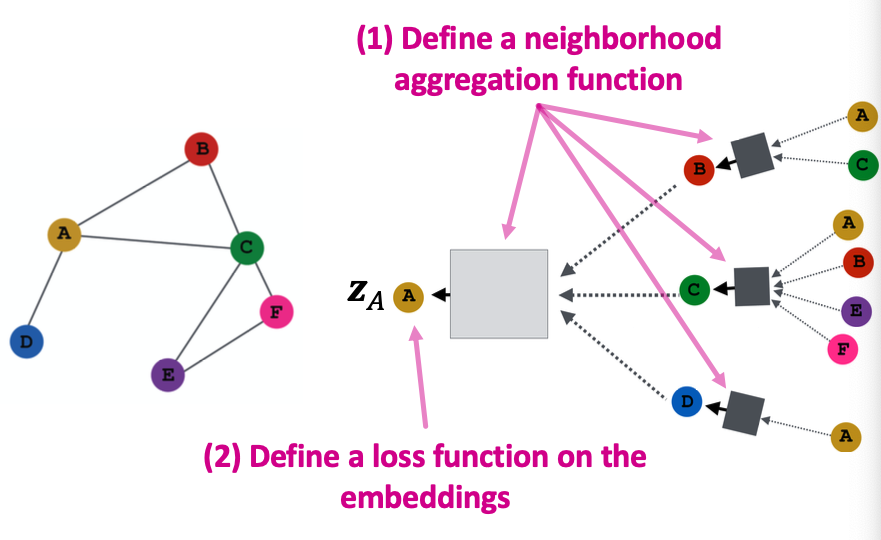
How do we train the GCN to generate embeddings?
Need to define a loss function on the embeddings.
Model Parameters
- are trainable weight matrices.
- : the hidden representation of node at layer .
- : weight matrix for neighborhood aggregation
- : weight matrix for transforming hidden vector of self.
Matrix Formulation
- Many aggregations can be performed efficiently by (spare) matrix operations
- Let
- Then:
- Let be diagonal matrix where
- The inverse of : is also diagonal:
- Therefore,
- Re-writing update function in matrix form:
where
- : neighborhood aggregation
- : self transformation
- 在真实情况下,可以用于稀疏矩阵(spare matrix)
Train A GNN
- Node embedding is a function of input graph.
- Supervised setting: We want to minimize loss :
- : node label
- could be if is real number, or cross entopy if is categorical
- Unsupervised setting:
- No node label available
- Use the graph structure as the supervision!
Unsupervised Training (无监督训练)
- “类似的”节点有着相似的嵌入
- where when node and are similar
- and is the dot product
- CE is the cross entropy loss:
-
- and are the actual and predicted values of the -th class.
- Intuition: the lower the loss, the closer the prediction is to one-hot.
-
- Node similarity can be anything from Random walks or Matrix factorization
Supervised Training (监督训练)
Directly train the model for a supervised task (e.g. node classification)
Use cross entropy loss
- : Node class label
- : Encoder output: node embedding
- : Classification weights
Model Design: Overview
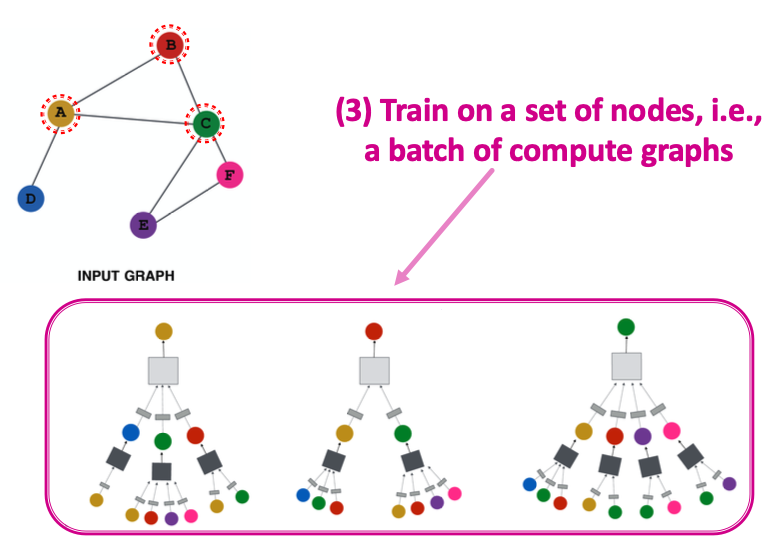
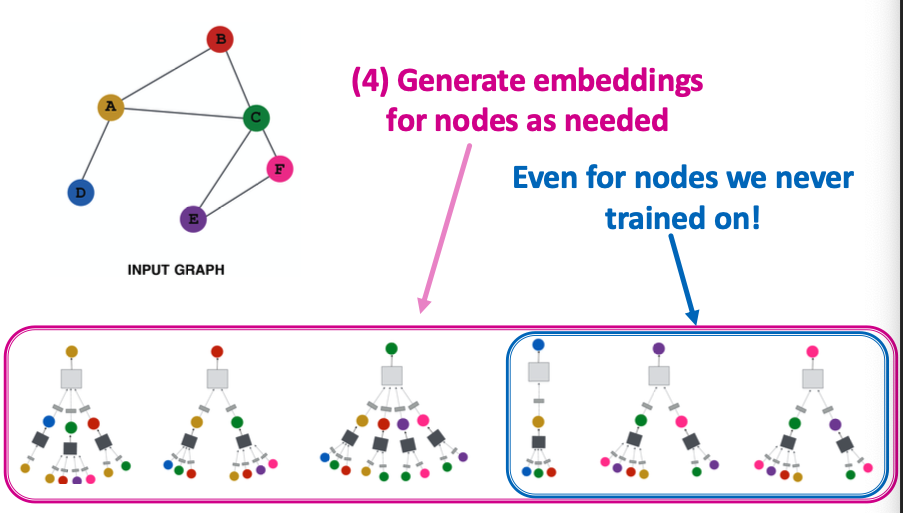
Inductive Capability (归纳)
The same aggregation parameters are shared for all nodes:
- The number of model parameters is sublinear in and we can generalize to unseen nodes!
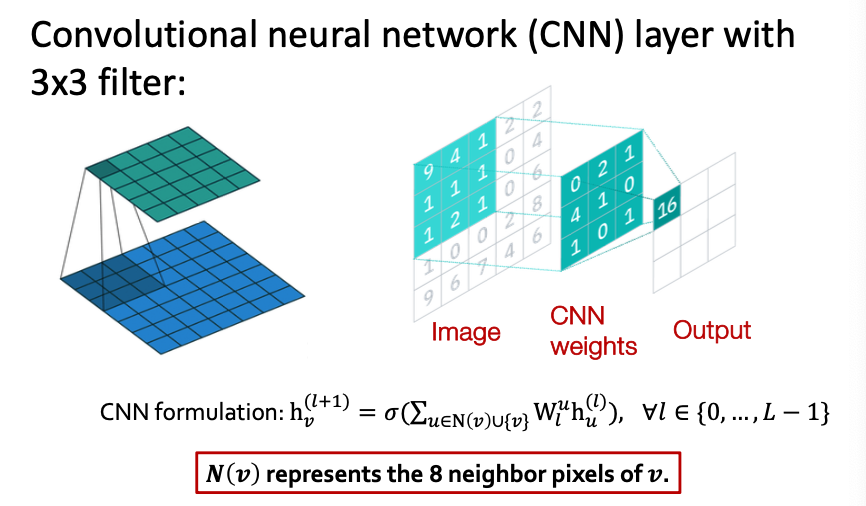
GNNs subsume CNNs
GNN CNN Transformer
Convolutional Neural Network
CNN vs. CNN
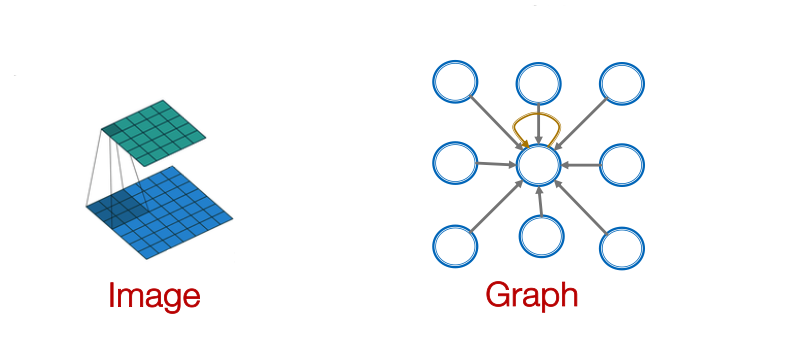
- GNN formulation:
- CNN formulation: (previous slide)
Key difference: We can learn different for different “neighbor” for pixel on the image. The reason is we can pick an order for the neighbors using relative position to the center pixel:
Key component: Self-attention
- Every token/word attends to all the other tokens/words via matrix calculation.
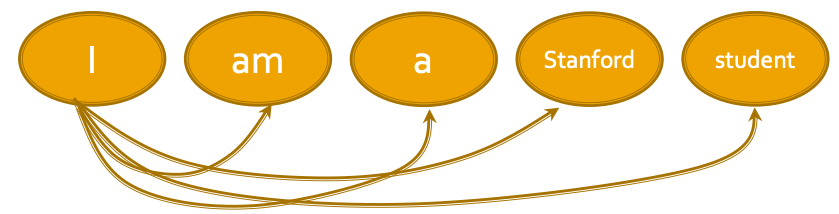
Definition: A general definition of attention: Given a set of vector values, and a vector query, attention is a technique to compute a weighted sum of the values, dependent on the query.
Transformer layer can be seen as a special GNN that runs on a fully connected “word” graph!